
BYUCTF was a CTF organized by CSA - Cybersecurity Student Association during the period of May 27th to May 28th.

We proudly got 5th Place among 435 Competing Teams.
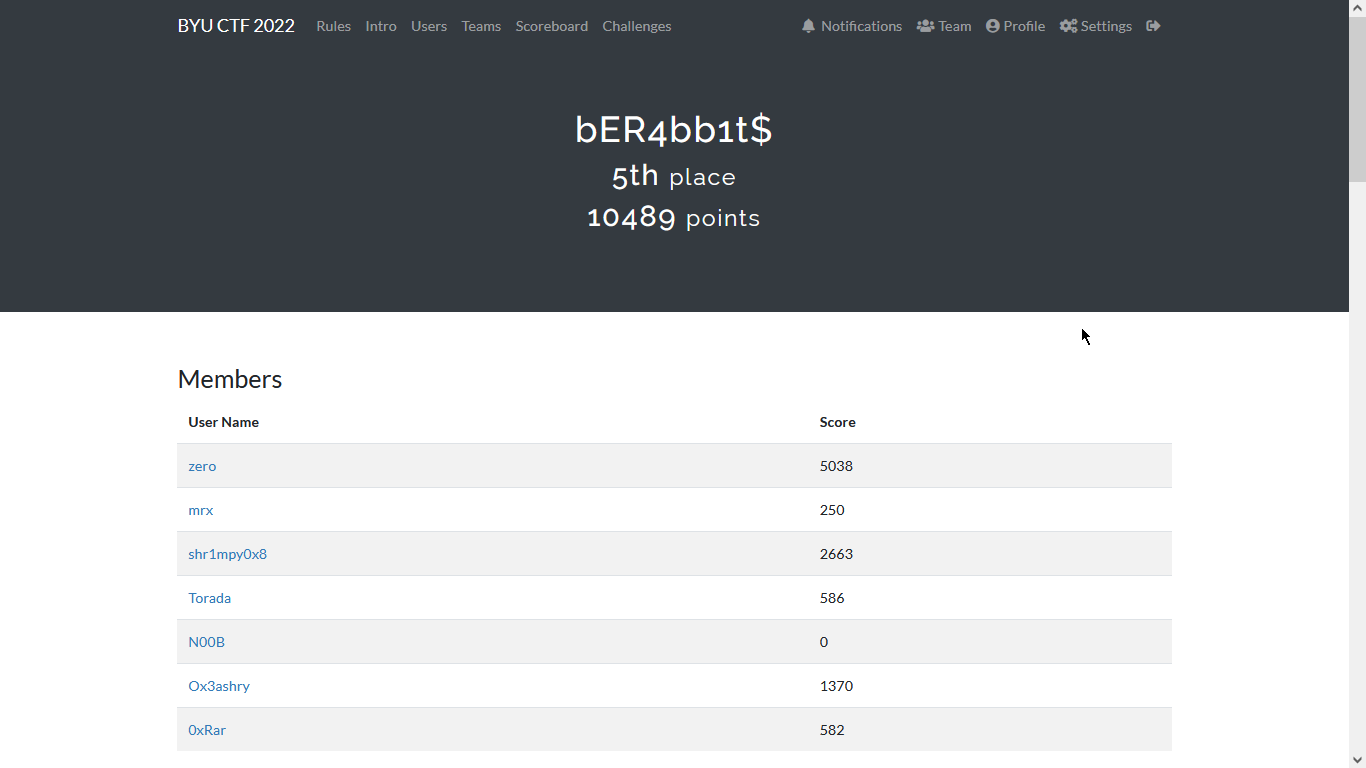
Web - Wordle
Wordle was an easy web challange that is inspired from the Wordle game.
Basically the game rules is that there is an English 5-letter word you must guess it through try and error, You have only 6 tries. In each try letters are colored by 3 colors Red, Orange and Green. Red means that this letter is incorrect, Orange means it is correct but in the wrong order and green means it is correct and in the right order in the original word.
You must use these informations try after try to guess the right word.\
Let’s move to the challange…
It is said in the challange to access http://byuctf.xyz:40003

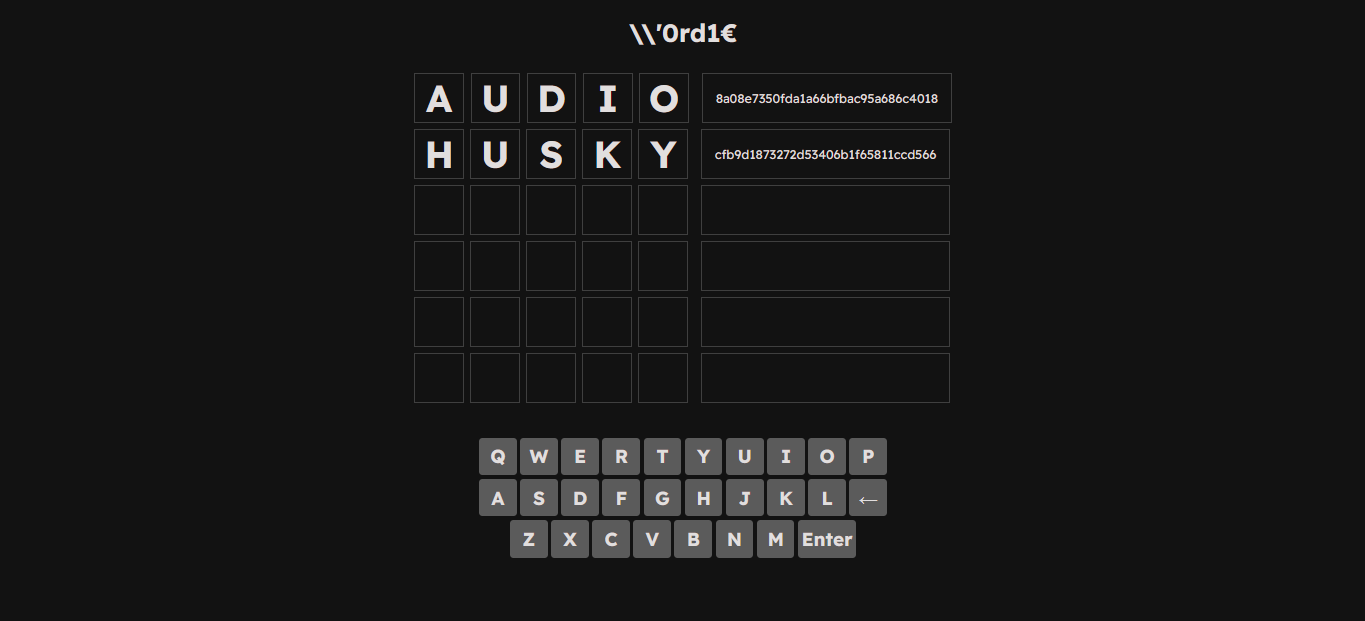
I tried the first word AUDIO but it gave me a hash…

There was a zip file attached with the challange so I extracted it, it contains 2 files for the website source code:
- app.py
- utils.py
There was nothing useful except in the utils.py I found getHashString function:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def getHashString(guess_status):
# guess_status[g_pos] = {"letter":g_char, "state":1}
passString = ''
for i in guess_status:
if i["state"] == 0:
passString += '⬛'
elif i["state"] == 1:
passString += '🟨'
elif i["state"] == 2:
passString += '🟩'
else:
passString += '?'
hashString = hashlib.md5(passString.encode('utf-8')).hexdigest()
return hashString
It takes my guessed word and append its color to passString and then has that string and return it and this is the hash which I saw on the website, instead of coloring the letters themselves they throw a hash.
First I generated all the possible combinations from 0:2.
0 is equivalent to Red 1 is equivalent to Orange 2 is equivalent to Green
and then maipulate getHashString a little bit so that it deals with guess_status as numbers instead of a dictionary and then append the generated hash to all_hashes.
function hash_to_colors take the hash and search for it in all hashes and return the corrosponding combination of colors (5 digit integer from 0:2)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
import hashlib
def getHashString(guess_status):
# guess_status[g_pos] = {"letter":g_char, "state":1}
passString = ''
hashString = ''
for i in guess_status:
if i == '0':
passString += '⬛'
elif i == '1':
passString += '🟨'
elif i == '2':
passString += '🟩'
hashString = hashlib.md5(passString.encode('utf-8')).hexdigest()
return hashString
combinations = []
for a in range(3):
for b in range(3):
for c in range(3):
for d in range(3):
for e in range(3):
value = str(a) + str(b) + str(c) + str(d) + str(e)
combinations.append(value)
all_hashes = []
for i in range(len(combinations)):
all_hashes.append(getHashString(combinations[i]))
def hash_to_colors(hashh, all_hashes, colors):
for i in range(len(all_hashes)):
if hashh == all_hashes[i]:
return colors[i]
# print(hash_to_colors('', all_hashes, combinations)) # 1st Try
# print(hash_to_colors('', all_hashes, combinations)) # 2nd Try
# print(hash_to_colors('', all_hashes, combinations)) # 3rd Try
# print(hash_to_colors('', all_hashes, combinations)) # 4th Try
# print(hash_to_colors('', all_hashes, combinations)) # 5th Try
# print(hash_to_colors('', all_hashes, combinations)) # 6th Try
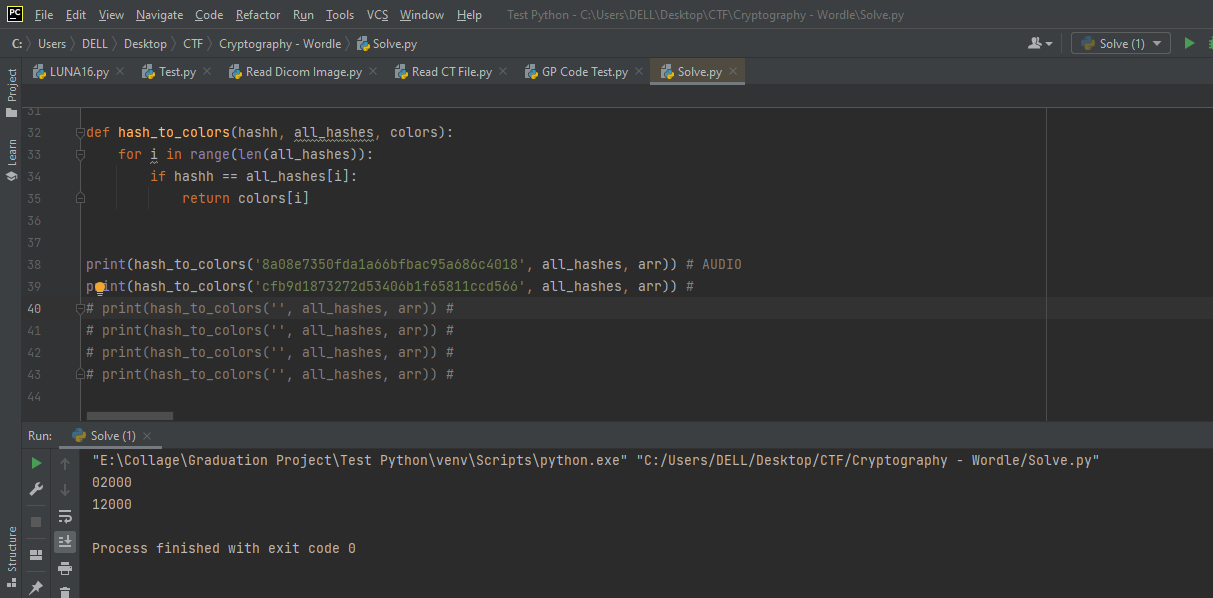
I took the generated hash and paste it in hash_to_colors and it gave me 02000 which means that only letter U is correct and in the right order
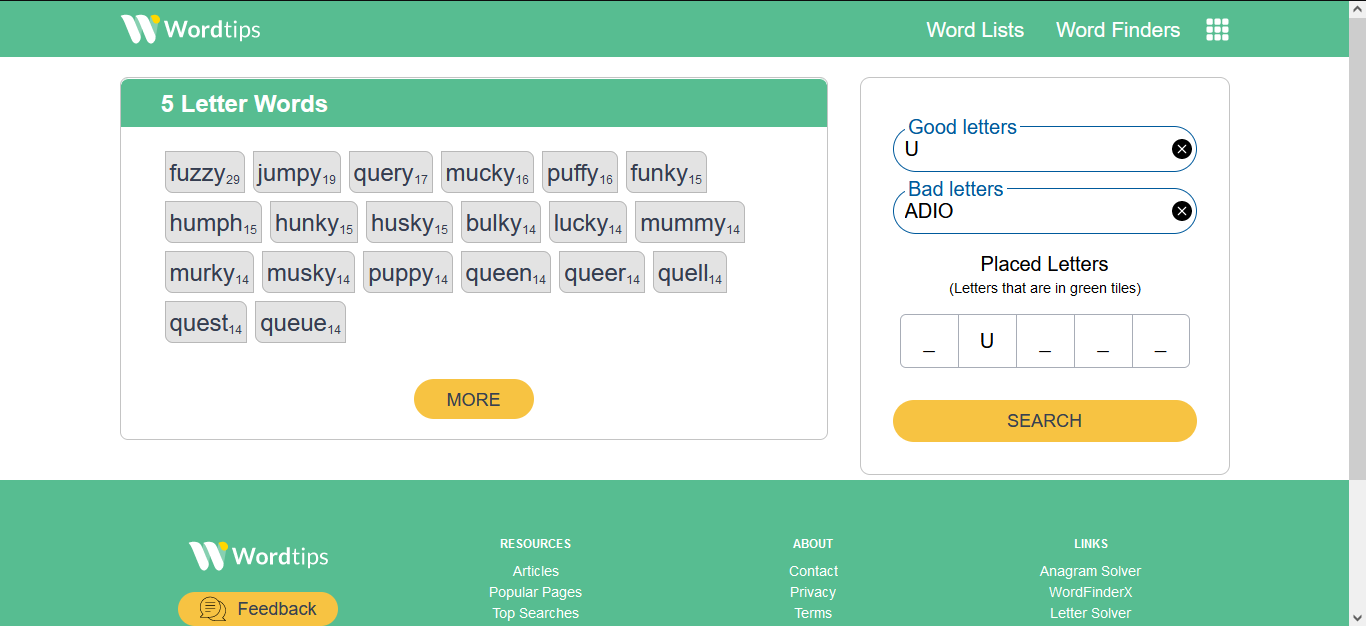
I used a website to help me solve wordle game faster: https://word.tips/, It gave me a lot of options to try next discarding the bad letters.
I tried HUSKY next and continue the same process…
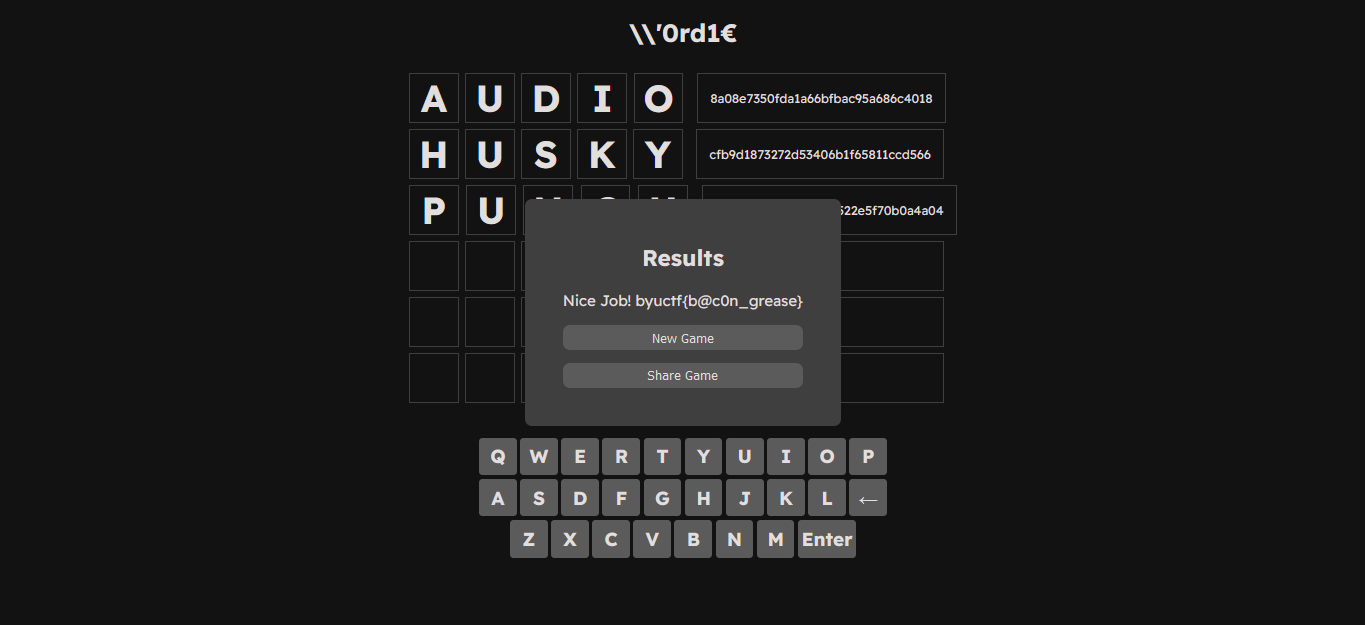
Let’s try PUNCH
BOOOOOOOOOOOOOOOOOOOM !!! We got the flag byuctf{b@c0n_grease}
Cryptography - XQR
XQR was a hard rated cryptography challange and it was in a whole another level.
It doesn’t contain except one massive image contain thousands of QR Codes
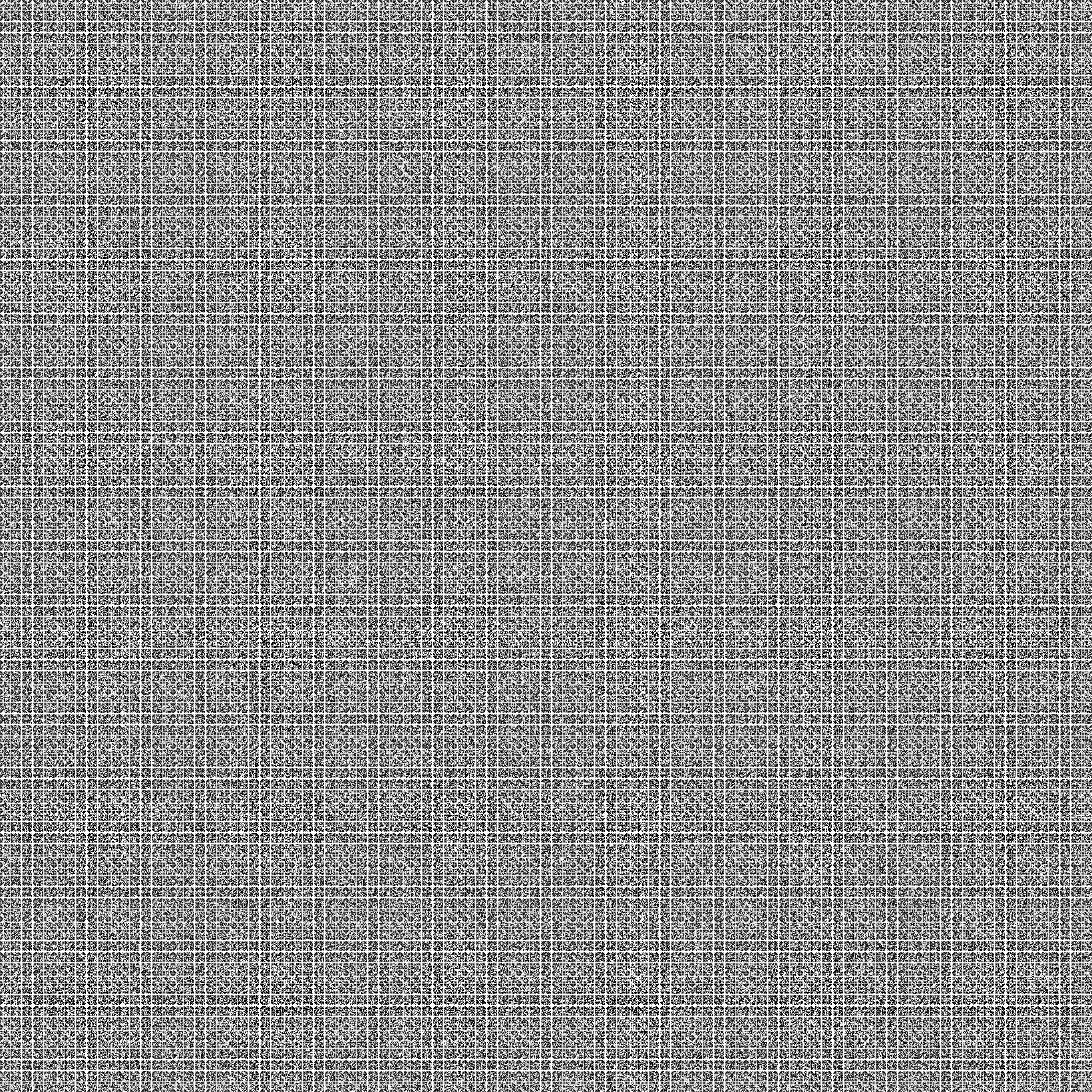
I first tried to read the first QR Code but it gave me 85TK6eDfb{SXQfvR70VXX !!!
Through trial and error I got that the size of each qr code is 27 pixels length and width, so i thought that cutting the whole image into smaller QR codes will make it easier
1
2
3
4
5
6
7
8
9
from PIL import Image
imggg = Image.open('xqr.png')
inc = 27
for i in range(0, 2727 , 27):
for j in range(0, 2727, 27):
box = (j, i, j+27, i+27) # left, top, right, buttom
img2 = imggg.crop(box)
img2.save(r'QRCodes/myimage_' + str(i) + '_' + str(j) + '_cropped.jpg')
Now I have 10,201 QR Codes stored in file called QRCodes, And I stucked for a while…
Then I realized from the name of the challange that XQR is near to XOR so what if I XORed all the QR codes together…
I started with reading them using cv2 library from python-opencv and then in order to make my trick work I changed the readed image to binary 0 and 1, black and white pixels. Then I XORed each pixel with the same pixels in all the other 10,201 qr codes and saved it, Then displaying the result shows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import cv2
import matplotlib.pyplot as plt
import os
QR_dir = os.listdir(r"QRCodes")
qr_codes = []
for qr in QR_dir:
gray = cv2.imread("QRCodes/" + qr, cv2.COLOR_BGR2GRAY)
_, binary = cv2.threshold(gray, 150, 1, cv2.THRESH_BINARY_INV)
qr_codes.append(binary)
for i in range(27):
for j in range(27):
for q in range(len(qr_codes)):
if q+1 == 10201:
break
qr_codes[0][i][j] ^= qr_codes[q+1][i][j]
plt.imshow(qr_codes[0])
plt.show()

Scanning it with my phone…
BOOOOOOOOOOOOOOOOOOOM !!! We got the flag byuctf{x0r_i5_u5eful}
Miscellaneous - Reconstruct
Reconstruct was a medium miscellaneous challange that was new and challanging to me…
First he gave ma an MD5 hash for the flag to verify that this is the flag before submission.
Whatever let’s download the file, It is an image containing the flag but was covered with a black bold line…

At the end of the file, The lower-case Alphabet and the numbers were attached to use them in the process of identifying the flag…
I solved it manually by comparing the sizes of the letters, and here were the steps:
The Underscore
_was obviously so I wrote the flag format as this:byuctf{XXXX_XXXX_XXX_XXXXXXXX_XX_XXXX_X_XXX_XXXXXXXXXXX_XX}Then I detected the characters with 2 tips down as the
h,nbyuctf{XXXn_XXXh_XhX_XXXXXXXX_XX_XnXX_X_XXn_XXXXnXXXXXX_XX}The number
1also was obviousbyuctf{XXXn_X1Xh_XhX_X1XXXXXX_XX_1nXX_1_XXn_XXXXnXXXXXX_1X}There were 2 simillar letters which were
t and lboth of them are written nearly close to each other with one small different which is thetletter’s down tip has a taller curvebyuctf{XXXn_X1th_thX_l1ttlXXt_XX_1nXX_1_XXn_XXXXnXtXXXt_1t}The
falso was pretty obviousbyuctf{XXXn_X1th_thX_l1ttlXXt_Xf_1nfX_1_XXn_XXXXnXtXXXt_1t}I was stuck to differentiate between
a,c,e,o,s,uall of them have a curve and very similar to each other, but the letterohave a more perfect circle when you focus morebyuctf{XXXn_X1th_thX_l1ttlXXt_of_1nfo_1_XXn_XXXXnXtXXXt_1t}After sometime I noticed that the
v,w’s tips are little bit more bold and centered in the middle of the letter’s placebyuctf{XvXn_w1th_thX_l1ttlXXt_of_1nfo_1_XXn_XXXXnXtXXXt_1t}there were remaining tips that are shifted leftward and isn’t classified yet, I had no option except the
rletter which was a smart choicebyuctf{XvXn_w1th_thX_l1ttlXXt_of_1nfo_1_XXn_rXXXnXtrXXt_1t}the third word was obvious to be
the
Now the generated words are: XvXn with the littlXXt of info i XXn rXXXnXtrXXt it
XvXn –> can’t know what it is
l1ttlXXt –> guessed to be l1ttlest
XXn –> can’t know what it is
rXXXnXtrXXt –> I count the number of letters and they happened to be equal to the word reconstruct which is the challange name, Bingooooo
Now the flag is byuctf{XvXn w1th the l1ttlest of 1nfo 1 XXn reconstruct 1t} I guessed the word XXn –> can
Then stucked for a while trying words that similar to XvXn and figured out that it is even
Now my flag is byuctf{even_w1th_the_l1ttlest_of_1nfo_1_can_reconstruct_1t}
To validate it I ran this script to generate the flag’s hash and compare it to the one in the description…
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def validate(strr, hash):
strr = hashlib.md5(strr.encode('utf-8')).hexdigest()
if strr == hash:
print("True")
else:
print("False")
def validate2(strr, hash):
strr = strr[7:-1]
strr = hashlib.md5(strr.encode('utf-8')).hexdigest()
if strr == hash:
print("True")
else:
print("False")
flag = "byuctf{even_w1th_the_l1ttlest_of_1nfo_1_can_reconstruct_1t}"
validate(flag,"63b1424fa6fe8aa81d9ce4b5637f7acd")
BOOOOOOOOOOOOOOOOOOOM !!! The flag was right
Miscellaneous - Probably
Probably was an easy Miscellaneous challange that uses netcat to connect to byuctf and displays some sort of message…
I connected to the server using windows version of netcat:
1
nc64.exe byuctf.xyz 40004
It displayed a large message and disconnected, rerun it again it displays different undefined message and disconnected
There was a python script attached with the challange, I opened it and found it does the following:
Opens the flag file and read it
Calls
random_stringfunction which changes the characters of the flag according to a random number from 0:1, If the random number < 0.25 the current character remains as it is, else it is replaced with another random characterThen the generated string
(new_string)will be displayed usingpyfiglet.figlet_formatfunction which displays it in the format we saw in the cmd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
#!/usr/bin/env python3
import string
import random
import pyfiglet
from pathlib import Path
import os
def open_file(filename):
'''
open a file by name and return the first line
'''
with open(filename, 'r') as f:
file = []
for line in f.readlines():
file.append(line.strip())
return file
def random_string(s):
'''
randomly changes characters in the string
returns the new string
'''
new_string = ''
for char in s:
print("Original char = " + char)
if random.random() < 0.25:
# print("[1] - " + str(random.random()))
new_string += char
else:
new_char = random.choice(string.ascii_lowercase + string.digits + "_")
print("[2] - " + str(new_char))
new_string += new_char
print()
return new_string
def main():
flag = open_file(os.path.join(os.path.abspath(
os.path.dirname(__file__)), 'flag.txt'))
print()
print(flag)
print(random_string(flag))
#print(pyfiglet.figlet_format(random_string(flag)))
if __name__ == "__main__":
main()
If I could store number of strings I can use the fact that there is 25% chance that the actual letter remains as it is and 75% it is replaced with another random letter, So what about generating 20 string and in each character calculate the most appeared character which in most casses will be the actual letter from the flag.
Let’s test my theory…
I ran the netcat connection 20 times and wrote the returned string in a separate text file and this was the result:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
by9ctfi48xz_mku8hhzpheaqceh1p5yp9p9s}
ndu7pd{wtg55pxy3dedr2hrngtqhgeehdflm3
brunufoohsruai__bujgi5hoaexqaeeu3ocbi
2nr0136wrfmwdveao2o_ih22cnb_2h4qlpckh
bkyumf1w6tymacasthwkc9slclw6ug0r6mc2c
lbeiefvihid_l2e5ime_cfl0oee_5spqw0csy
2rscm_qghpnxatjt0h1zch_hc2ec3keozntgi
oypbrjt2hbn2are_mghveprkxns_3oeppfc5z
b6uytx6w8atndrlxblv9cmynvew35cap2ifs}
g36ki2mwhkqpxjegtxdpcxa_tesmb1em3dab3
eylvk7la8elnarp_t_6_n8qa1buohxqewua2s
b8u2xfk1ha5a1ran8hu_8hnncxue798mhfcl}
fwusmfj_0kt_nrh1th7hmb2ns71_3kl5n_18}
youqtfzvhuva09etphik3hoc3_rt7cep32dhl
byujrnd41a5_t4d6tkeqc7af09vm36mkhycsb
0vrrxsvw7qbzbpybb6s_6hanunq51e_hjfsp}
2y9zqfowhmtns864n8s_yilqchaw7de6pn0mq
lk43zix74wt2wb_e9sg_ahxncyscte_p_cc1w
1y9caeywkj4_drojahcz5_fnpks_7vjp158st
ggrf64jynpv_amm5zke3chnoqdthxlepjfas6
_yuclfuilae_jrj_1he_cx2nc1st3j795feuv
Then I wrote a python script that takes each letter and loops on the whole text file get the most appearing letter in this position and so on…
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
def open_file(filename):
'''
open a file by name and return the first line
'''
with open(filename, 'r') as f:
file = []
for line in f.readlines():
file.append(line.strip())
return file
def decrypt(flags):
# flags = ['by9ctfi48xz_mku8hhzpheaqceh1p5yp9p9s}', 'ndu7pd{wtg55pxy3dedr2hrngtqhgeehdflm3', 'brunufoohsruai__bujgi5hoaexqaeeu3ocbi', ...etc]
dict = {}
flag = ""
for i in range(len(flags[0])):
for j in range(len(flags)):
if flags[j][i] in dict.keys():
dict[flags[j][i]] += 1
else:
dict[flags[j][i]] = 1
bigger = 0
bigger_char = ''
for char in dict:
if dict[char] > bigger:
bigger = dict[char]
bigger_char = char
flag += bigger_char
dict = {}
return flag
enc_flags = open_file(r"encrypted_flags_simplified.txt")
x = decrypt(enc_flags)
print(x)
It generated: byuctfowhat_are_the_chances_3eep3fcs} which missed the { so I replaced it and BOOOOOOOOOOOOOOOOOOOM !!! The flag was right